
基本用法
Node.js默认单进程运行,对于32位系统最高可使用512MB内存,对于64位最高可以使用1GB内存。对于多核CPU的计算机来说,这样做效率很低,因为只有一个核在运行,其他核都在闲置。cluster模块就是为了解决这个问题而提出的。
cluster模块允许设立一个主进程和若干个worker进程,由主进程监控和协调worker进程的运行。worker之间采用进程间通讯交换消息,cluster模块内置一个负载均衡器,采用Round-robin算法协调各个worker进程之间的负载。运行时,所有新建立的链接都由主进程完成,然后主进程再把TCP链接分配给指定的worker进程。
cluster模块实际上就是
child_process模块跟其它模块的组合,更方便的创建集群,实际原理和child_process是一样的Round-robin算法的基本原理会在后面章节仔细说明
const http = require('http');
const cluster = require('cluster');
const os = require('os');
const cpuLen = os.cpus().length;
if (cluster.isMaster) {
for (let i = 0; i < cpuLen; i++) {
cluster.fork();
}
} else {
http.createServer((req, res) => {
const pid = process.pid;
res.writeHead(200);
res.end(`hello world from process: ${pid}`);
}).listen(3232);
}然后我们多刷新几次浏览器,就会发现可能得到的结果不一样,这也就说明了我们的服务被不同的worker进程处理了。
上面代码先判断当前进程是否为主进程(cluster.isMaster),如果是的,就按照CPU的核数,新建若干个worker进程;如果不是,说明当前进程是worker进程,则在该进程启动一个服务器程序。
上面这段代码有一个缺点,就是一旦work进程挂了,主进程无法知道。为了解决这个问题,可以在主进程部署online事件和exit事件的监听函数,在某个worker进程exit之后,就会立即重新启动一个新的worker进程。此处不在编写相关代码,可以查询相关Node.js资料。
说到这里,HTML5 提出的 Web Worker ,方式大同小异,解决了 JavaScript 主线程与 UI 渲染线程互斥,所引发的长时间执行 JavaScript 导致 UI 停顿不响应的问题。
另外申明一点:fork 线程开销是比较大的,要谨慎使用,并且我们 fork 进程是为了利用 CPU 资源,跟高并发没啥大关系。
另外一种创建Node.js服务集群的方案是通过代理的方式,但是由于缺陷明显,采用很少
进程之间通信
cluster.fork()会返回一个Worker的实例,借助send函数,我们可以从Master进程像每个worker进程发送消息,worker进程通过监听process.on('message')来接收消息,修改上面的示例代码如下:
// ...
if (cluster.isMaster) {
for (let i = 0; i < cpuLen; i++) {
const worker = cluster.fork();
workers.push(worker);
worker.send('[master] ' + 'send msg ' + i + ' to worker ' + worker.id);
}
} else {
process.on('message', function (message) {
console.log('get worker log:', message);
});
// ...
}以上代码打印结果如下:
get worker log: [master] send msg 0 to worker 1
get worker log: [master] send msg 2 to worker 3
get worker log: [master] send msg 3 to worker 4
get worker log: [master] send msg 1 to worker 2
get worker log: [master] send msg 5 to worker 6
get worker log: [master] send msg 4 to worker 5
get worker log: [master] send msg 7 to worker 8
get worker log: [master] send msg 6 to worker 7如果反过来,worker进程向Master进发送消息,道理是同样的,通过process.send发送消息,然后worker监听message事件。
同样我们可以通过监听worker进程的exit事件,在工作进程因为各种原因挂掉的时候通知Master重新开启一个工作进程。
还有一种多进程之间通信必须做的是:session保存与共享,我们一般在服务端使用session来保存用户的登录状态和用户信息,举个例子:
user.post('/login', (req, res) => {
let userInfo = req.body,
data;
User.find(userInfo, (err, docs) => {
if (err) throw err;
else {
if (docs.length > 0) {
// 需要引入express-session
// 往session中存入信息同样会往浏览器cookie中写入数据,作为对应和标记(如果没有写入cookie,则要检查请求,代理等操作是否允许写入)
req.session.user = docs[0],
data = {
code: 200,
msg: 'login successfully'
}
} else {
data = {
code: 400,
msg: 'Incorrect username or password.'
}
}
res.send(data);
}
})
});上述操作仅仅在当前进程记录了登录状态,但是如果另一个请求是被别的进程处理的,别的进程是不知道用户已经登录的,会重定向到登录页面,这样很明显是不对的,所以多个进程之间必须保持同步登录的状态,这个时候我们可以借助Mongo DB等NOSQL来完成:
const expressSession = require('express-session')
const MongoStore = require('connect-mongo')(expressSession);
app.use(expressSession({
secret: config.sessionSecret,
name: 'username',
saveUninitialized: false,
resave: true,
cookie: {
httpOnly: true,
maxAge: 1000 * 60 * 60 * 2,
},
store: new MongoStore({
url: config.sessionMongoUrl //mongo db connect url
})
}));Node.js 集群管理
PM2
上面介绍的Node.js集群是基于基础的API来实现的,我们可以发现各种错误处理,消息传递等等很是翻落,庆幸的是现在已有的成熟方案挺多的,比如PM2; 举个很常见的例子: 我们需要在Node.js进程发生错误退出的时候,快速重启不影响别的用户使用,同时在我们部署更新文件的时候,能够不停机的去部署应用,这个时候我们只要借助PM2就可以很快速的完成这些任务:
pm2 start index.js --watch其他具体的使用方式我们就不再继续讲述,直接看文档即可。
systemd
另一种方案是使用systemd运行Node.js。我不是很了解(或者说根本不知道systemd,我已经把这句话弄错过一次了,所以我会用 Tierney大佬自己的原话来表述:
“只有在部署中访问 Linux 并控制 Node 在服务级别上启动的方式时,才有可能实现此选项。如果你在一个长时间运行的 Linux 虚拟机中运行 node.js 进程,比如说 Azure 虚拟机,那么使用 systemd 运行 node.js 是个不错的选择。如果你只是将文件部署到类似于 Azure AppService 或 Heroku 的服务中,或者运行在类似于 Azure 容器实例的容器化环境中,那么你可以避开此选项。”
关于 systemd与Node.js的相关文介绍可以参考:
题外话 Nginx
说到集群怎么会没有Nginx的份呢,在一般的应用中不会直接用Node做负载均衡,而是会使用Nginx来转做,具体来说就是:
- 对于前端打过来的所有请求,在Nginx这里做请求的分发,打到Node.js集群的某个机器上。
- 健康检测,Node.js集群的及其同样有可能挂掉,所以会采用Nginx进行检测,发现挂了的及其,会干掉重启,保证其群的高可用。检测有两种机制,被动检测跟主动检测。
Nginx 是什么?
Nginx 作为一个基于C实现的高性能Web服务器,可以通过系列算法解决上述的负载均衡问题。并且由于它具有高并发、高可靠性、高扩展性、开源等特点,成为开发人员常用的反向代理工具。
Nginx正向代理
正向代理(Forward Proxy)最大的特点是,客户端非常明确要访问的服务器地址,它代理客户端,替客户端发出请求。比如:科学上网,俗称翻墙(警告⚠️:翻墙操作违反相关法律规定,本文只是为了解释正向代理向读者举个例子,仅供学习参考,切勿盲目翻墙)。
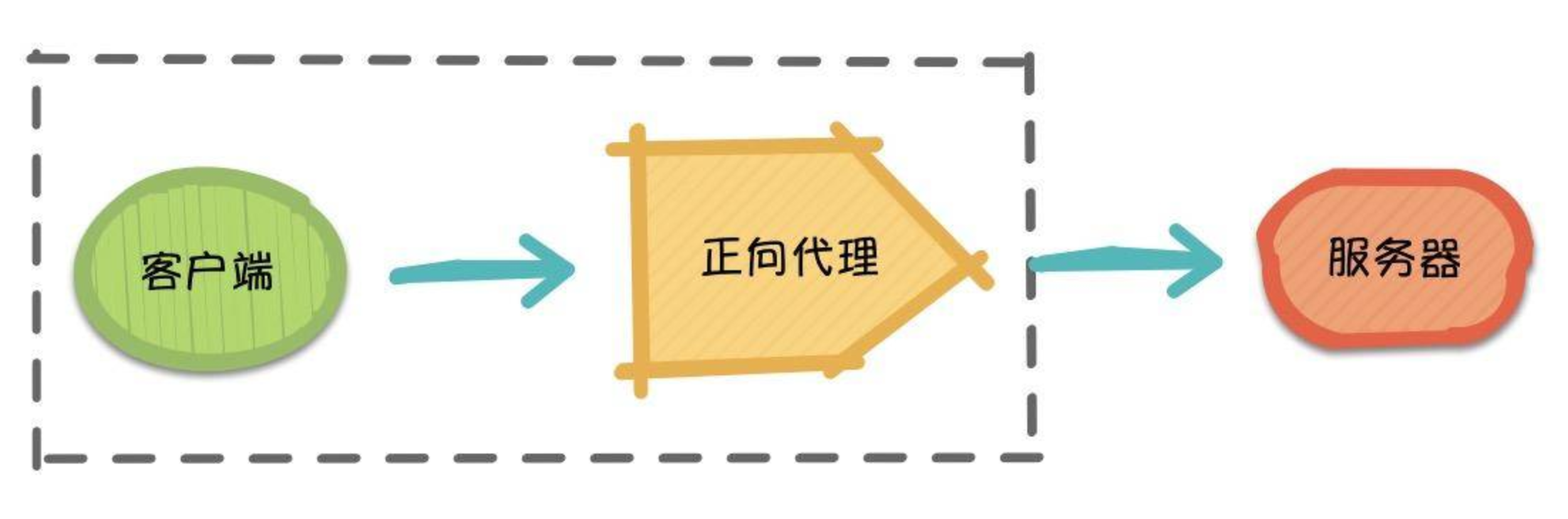
假设客户端想要访问Google,它明确知道待访问的服务器地址是www.google.com,但由于条件限制,它找… Google 的"朋友":代理服务器。客户端把请求发给代理服务器,由代理服务器代替它请求Google,最终再将响应返回给客户端。这便是一次正向代理的过程,该过程中Google服务器并不知道真正发出请求的是谁。
Nginx反向代理
那么,随着请求量的爆发式增长,服务器觉得自己一个人始终是应付不过来,需要兄弟服务器(集群)们帮忙,于是它喊来了自己的兄弟以及代理服务器朋友。 此时,来自不同客户端的所有请求实际上都发到了代理服务器处,再由代理服务器按照一定的规则将请求分发给各个服务器。
这就是反向代理(Reverse Proxy),反向代理隐藏了服务器的信息,反向代理代理的是服务器端,代其接收请求。换句话说,反向代理的过程中,客户端并不知道具体是哪台服务器处理了自己的请求。如此一来,既提高了访问速度,又为安全性提供了保证。
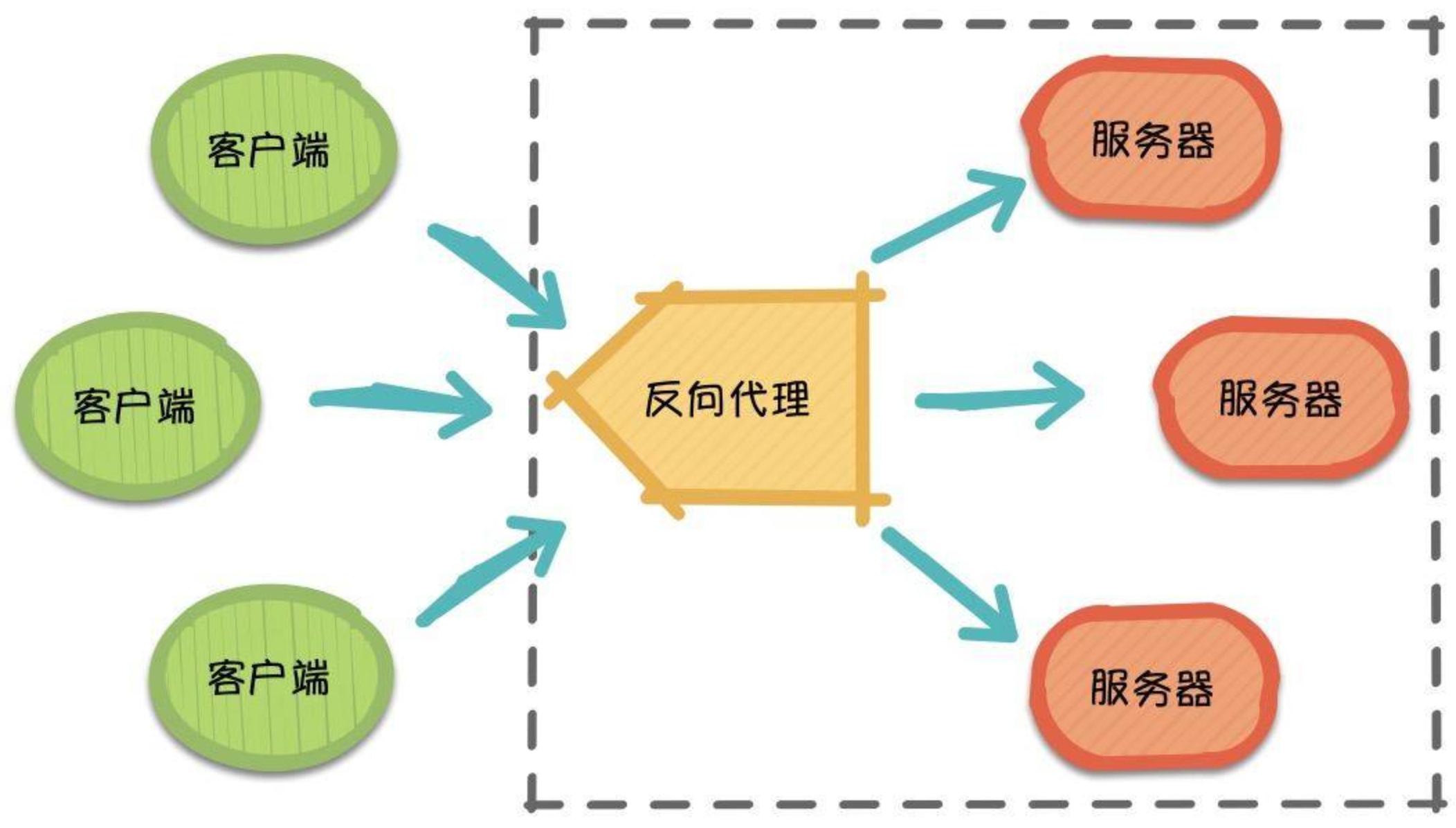
在这之中,反向代理需要考虑的问题是,如何进行均衡分工,控制流量,避免出现局部节点负载过大的问题。通俗的讲,就是如何为每台服务器合理的分配请求,使其整体具有更高的工作效率和资源利用率。
负载均衡常用算法介绍
轮询(round-robin)
Round-robin(轮询调度)算法的原理是每一个把来自用户的请求轮流分配给内部中的服务器,从1开始,直到N(内部服务器个数),然后重新开始循环。该算法的优点是及其简洁,它无需记录当前所有连接的状态,所以是一种无状态调度。
轮询调度算法假设所有服务器的处理性能都相同,不关心每台服务器的当前连接数和响应速度。当请求服务间隔时间变化比较大时,轮询调度算法容易导致服务器间的负载不平衡。所以此种均衡算法适合于服务器组中的所有服务器都有相同的软硬件配置并且平均服务请求相对均衡的情况。
加权轮询
为了避免普通轮询带来的弊端,加权轮询应运而生。在加权轮询中,每个服务器会有各自的weight。一般情况下,weight的值越大意味着该服务器的性能越好,可以承载更多的请求。该算法中,客户端的请求按权值比例分配,当一个请求到达时,优先为其分配权值最大的服务器。
特点:加权轮询可以应用于服务器性能不等的集群中,使资源分配更加合理化,其核心思想是,遍历各服务器节点,并计算节点权值,计算规则为current_weight与其对应的 effective_weight之和,每轮遍历中选出权值最大的节点作为最优服务器节点。
IP 哈希(IP hash)
ip_hash依据发出请求的客户端IP的hash值来分配服务器,该算法可以保证同IP发出的请求映射到同一服务器,或者具有相同hash值的不同IP映射到同一服务器。
特点:该算法在一定程度上解决了集群部署环境下Session不共享的问题。
Session不共享问题是说,假设用户已经登录过,此时发出的请求被分配到了A服务器,但A服务器突然宕机,用户的请求则会被转发到B服务器。但由于Session不共享,B无法直接读取用户的登录信息来继续执行其他操作。
实际应用中,我们可以利用ip_hash,将一部分IP下的请求转发到运行新版本服务的服务器,另一部分转发到旧版本服务器上,实现灰度发布。再者,如遇到文件过大导致请求超时的情况,也可以利用ip_hash进行文件的分片上传,它可以保证同客户端发出的文件切片转发到同一服务器,利于其接收切片以及后续的文件合并操作。
最小连接数(Least Connections)
假设共有M台服务器,当有新的请求出现时,遍历服务器节点列表并选取其中连接数最小的一台服务器来响应当前请求。连接数可以理解为当前处理的请求数。